Rapidminer 中文分词&&去除停用词
First: 打开Rapidminer新建项目
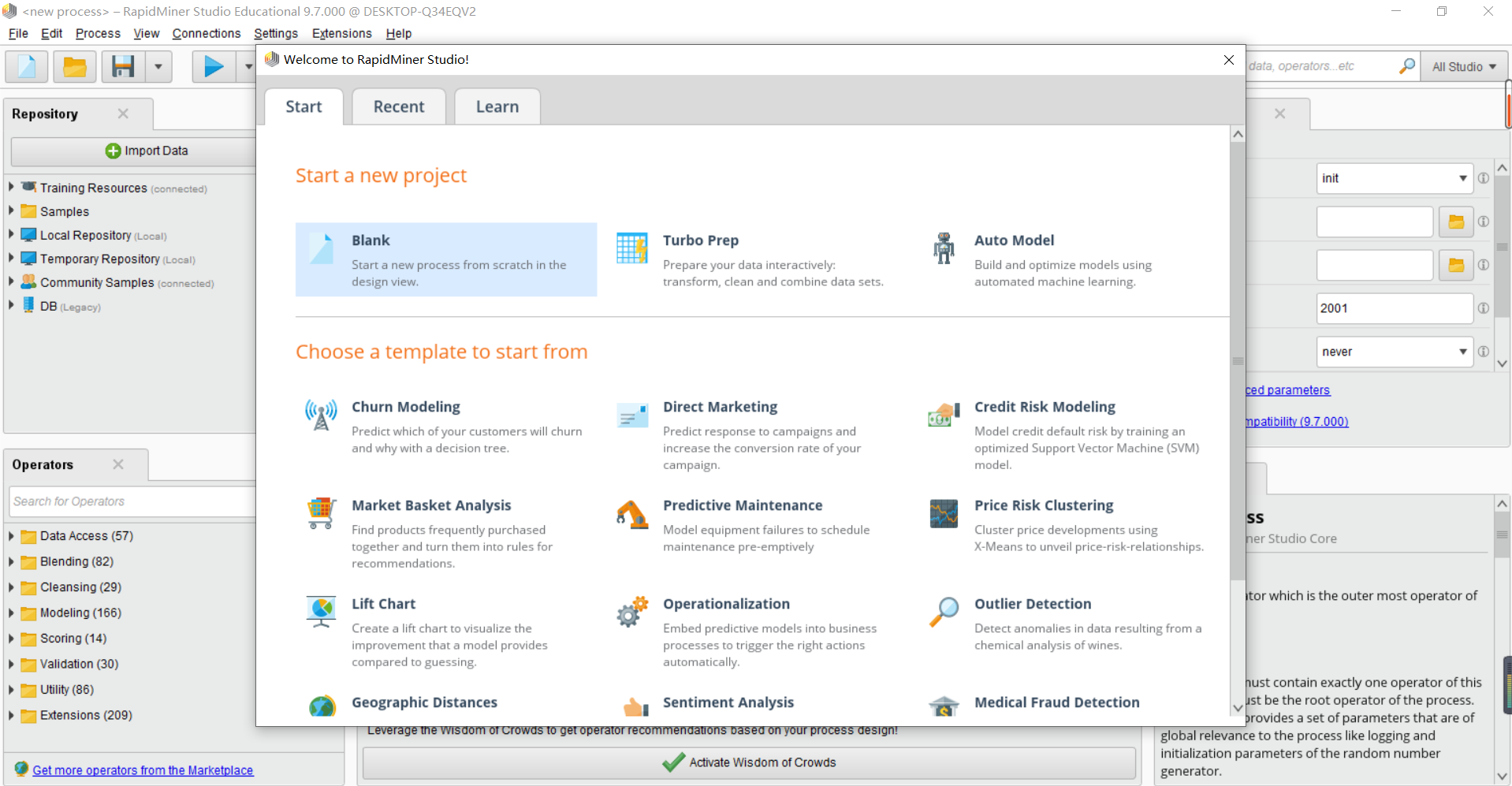
首先打开你的Rapidminer,选择新建Blank项目。
Second: 导入数据集&&导入停用词列表
导入的数据必须是清洗过后的数据,不要有脏数据。
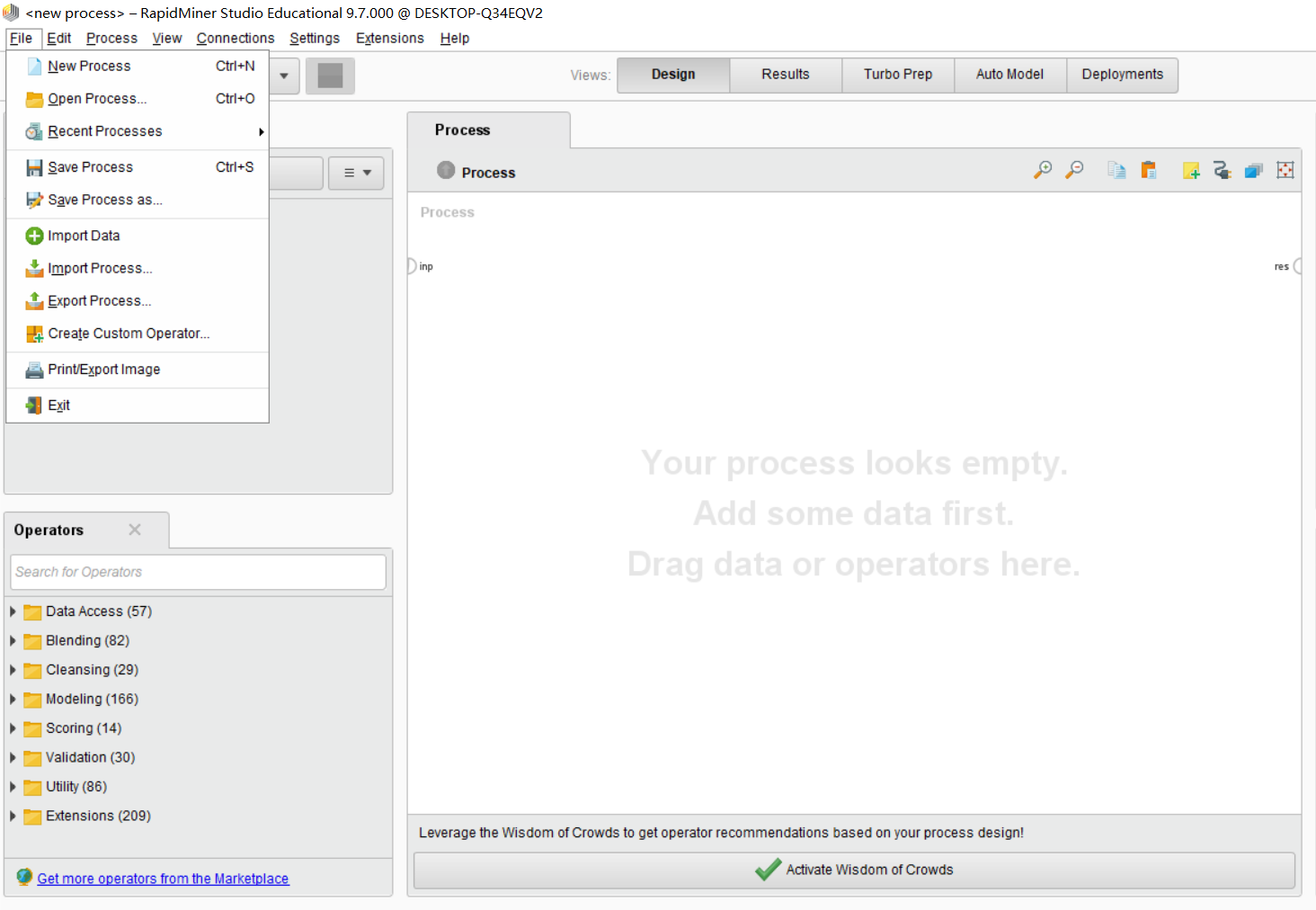
File,点击Import Data选项。会出现下面画面:
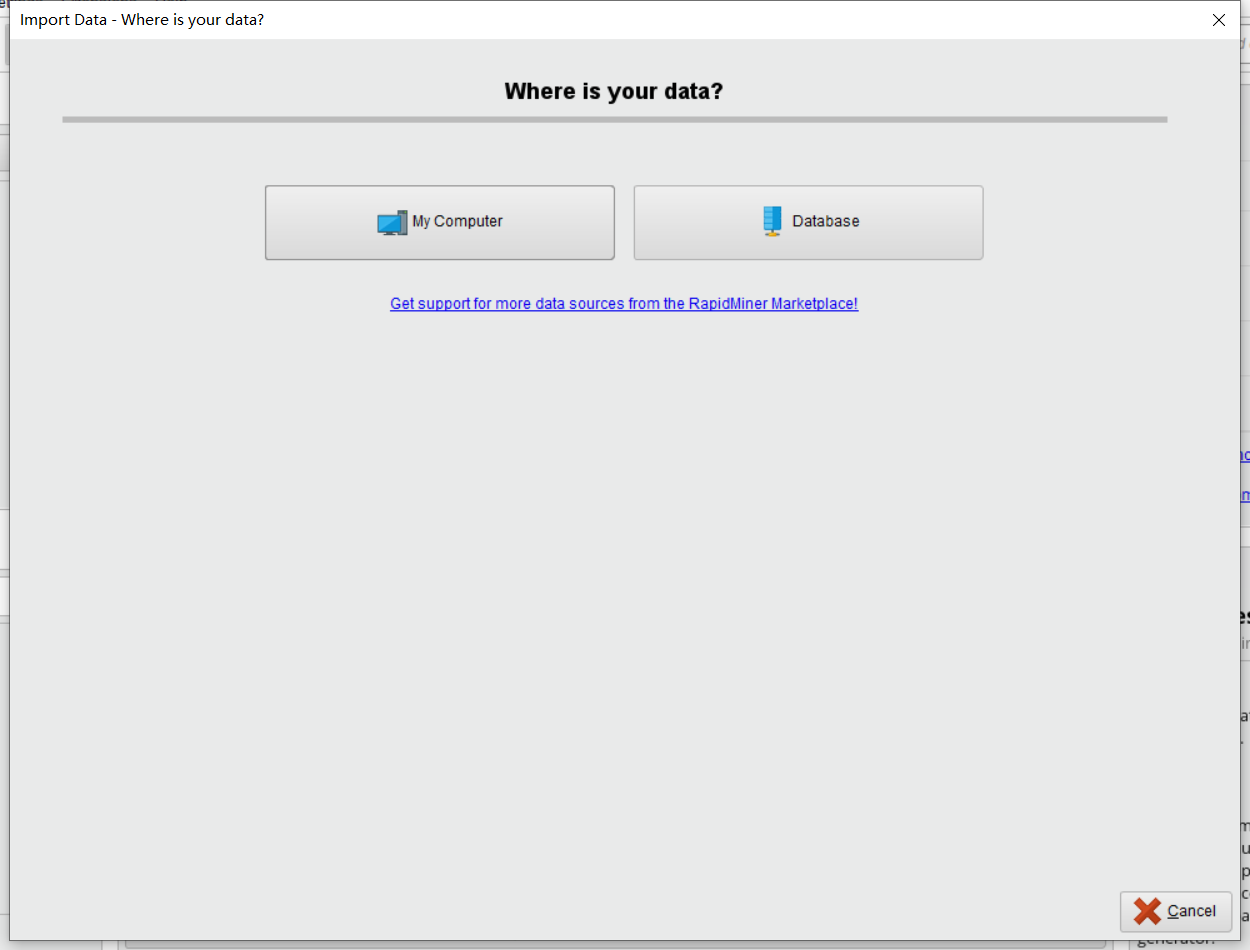
因为我们是要从本地导入数据集,所以我们选择My Computer。会出现下面画面:
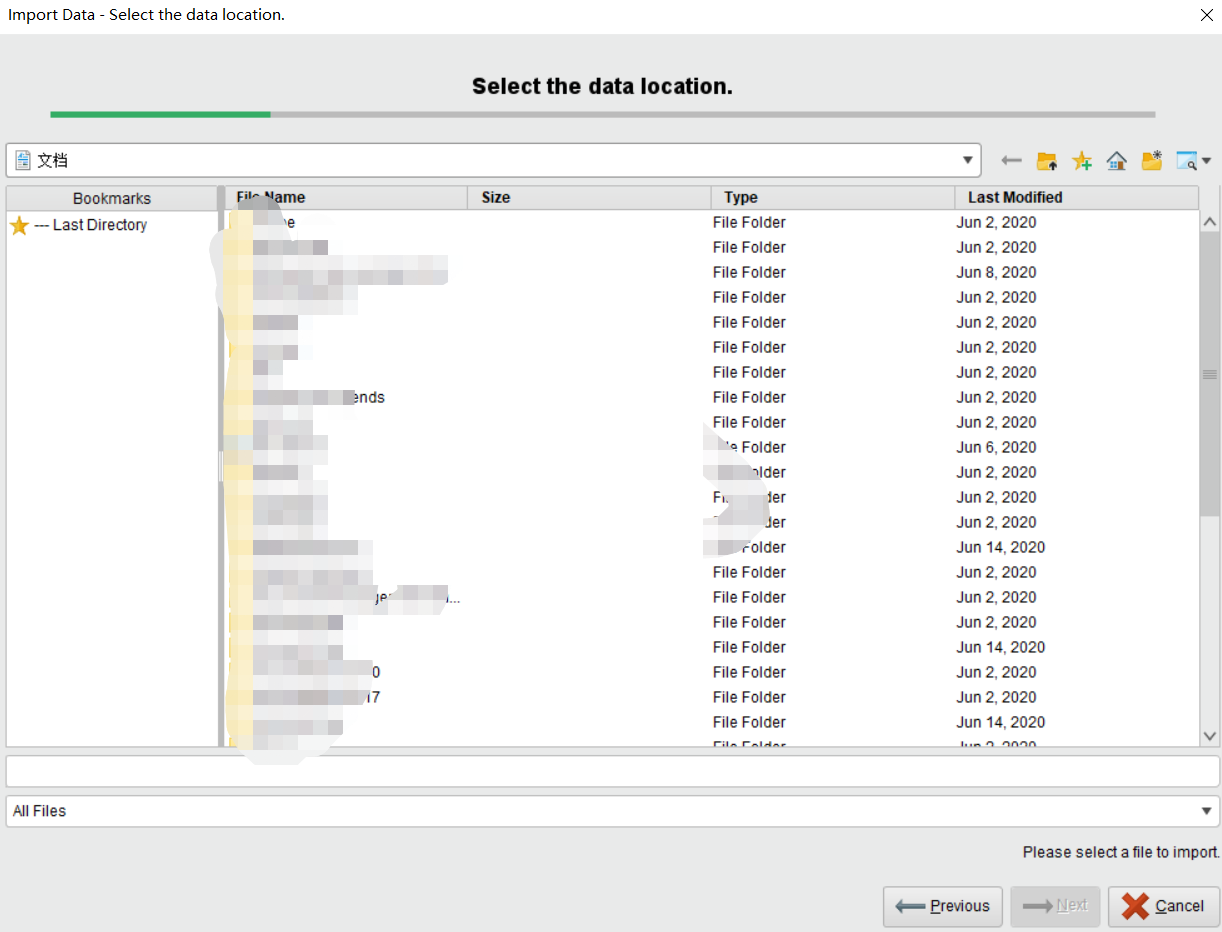
我们只需要找到我们想导入的数据集,然后点击next。这时候会出现以下画面:
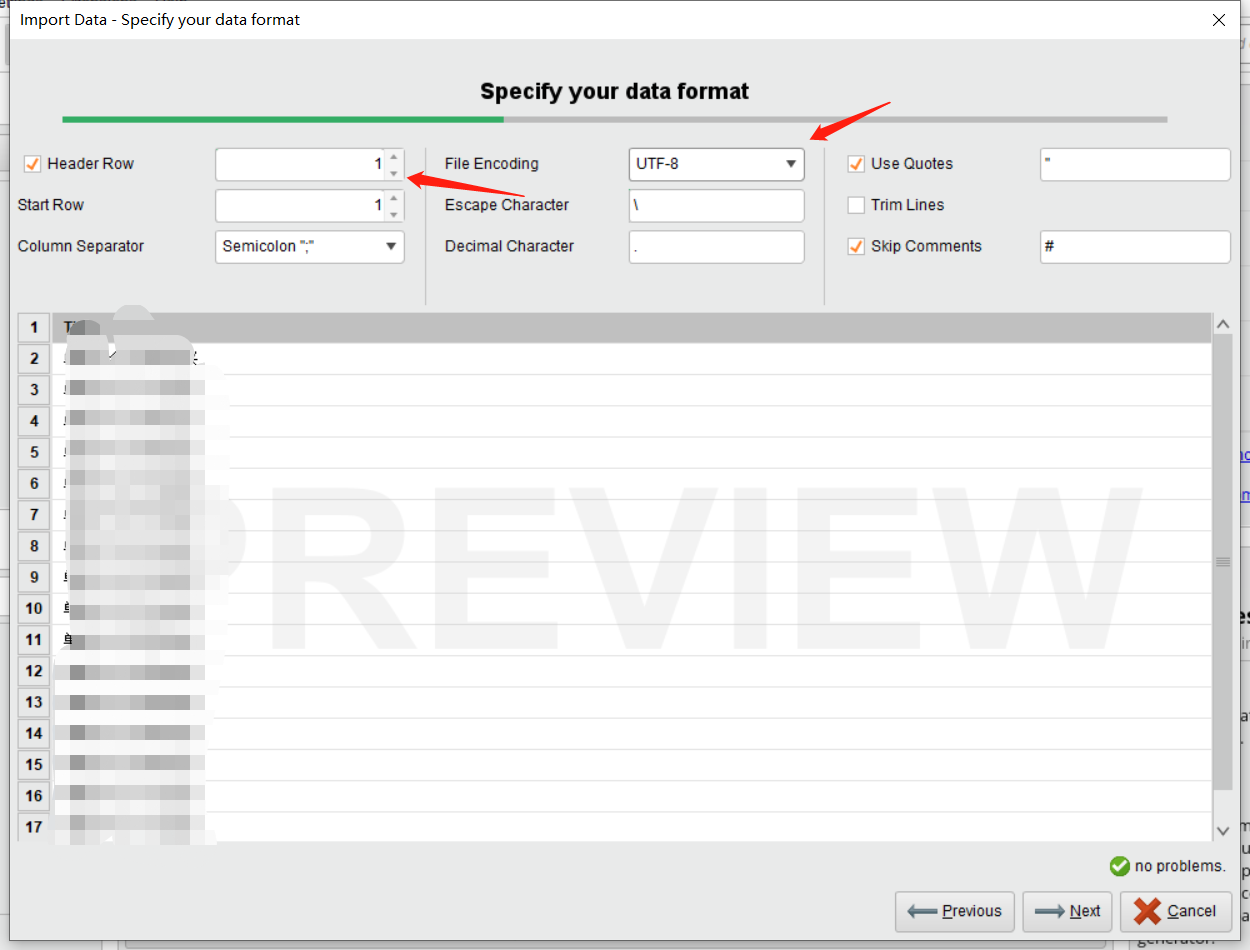
注意事项:File Encoding必须要选择UTF-8。Header Row根据实际情况去选择,一般数据集第一行为Header。
之后我们点击next。这时候会出现以下画面:
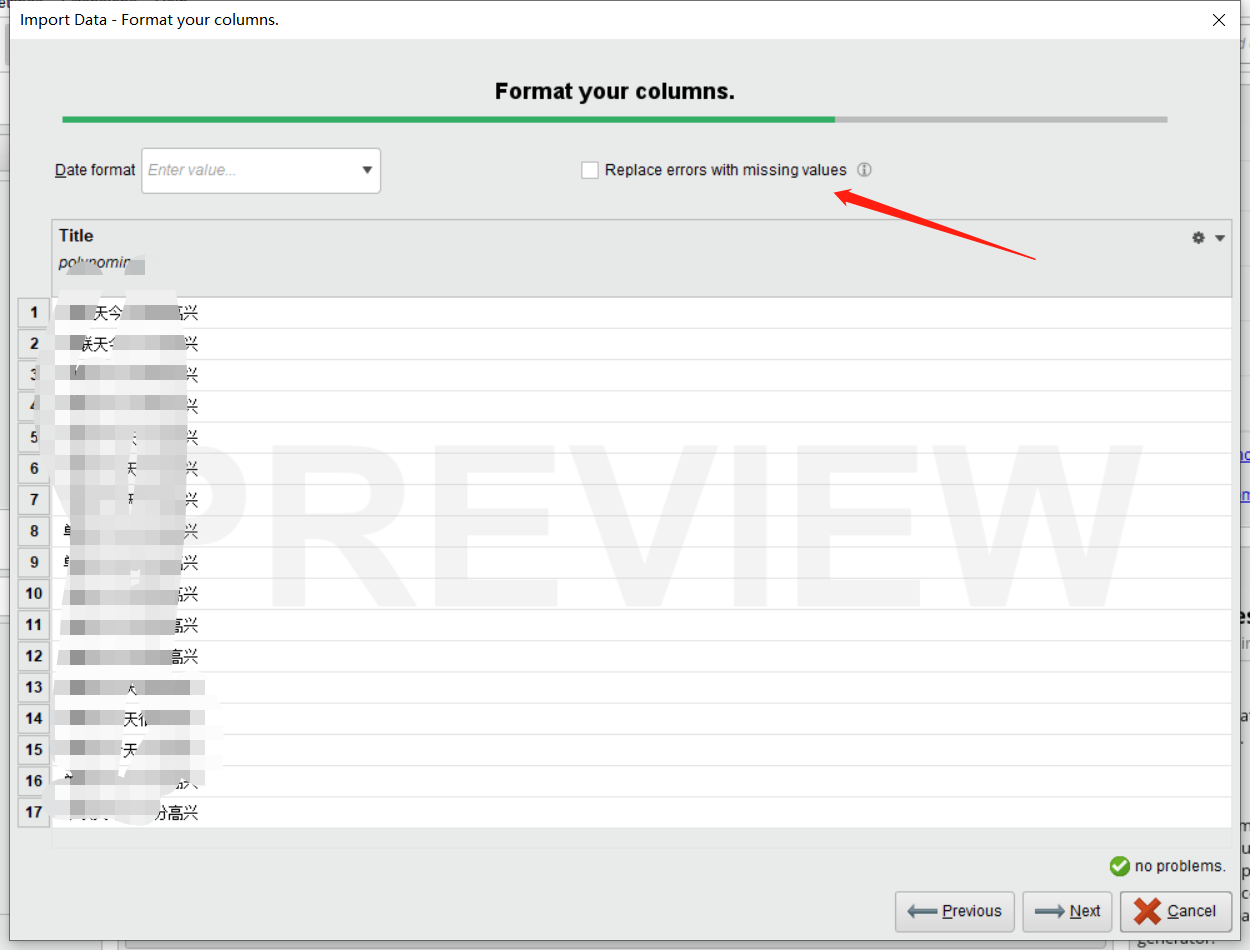
注意事项,右上角Replace errors with missing values是处理数据错误情况的,他是用None值填充的。以下过程必须保证你数据是被清洗过后的。
之后我们点击next,会出现下面界面:
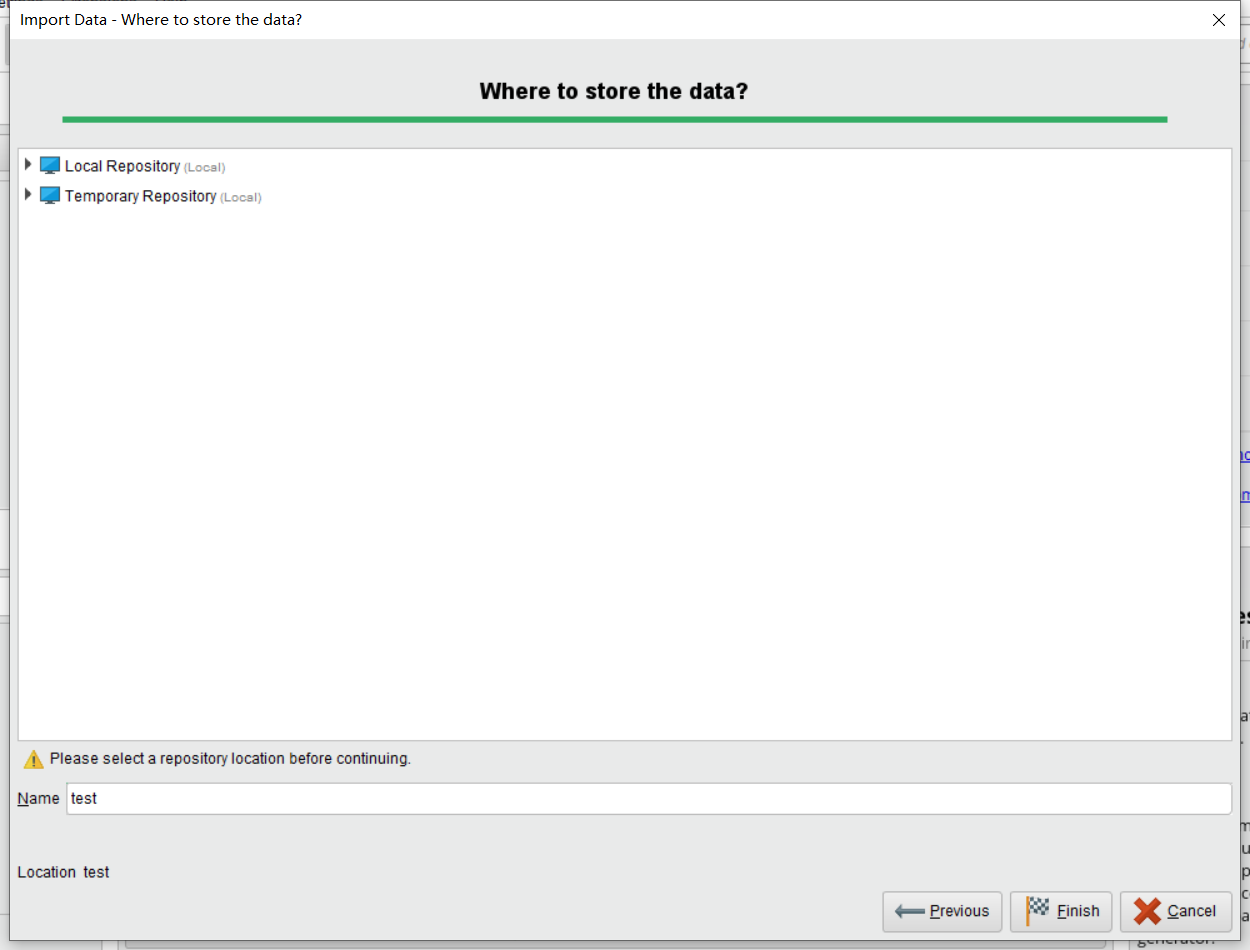
这里填写的是你的保存数据的地址,你只需要保证你保存后的地址能够找到即可。之后我们点击Finish。便可以完成了数据的导入。
同理我们导入停用词列表,原理方法一样。
Third: 构建整个流程
回到主界面,然后找到你导入的数据集,将其拖入主界面。
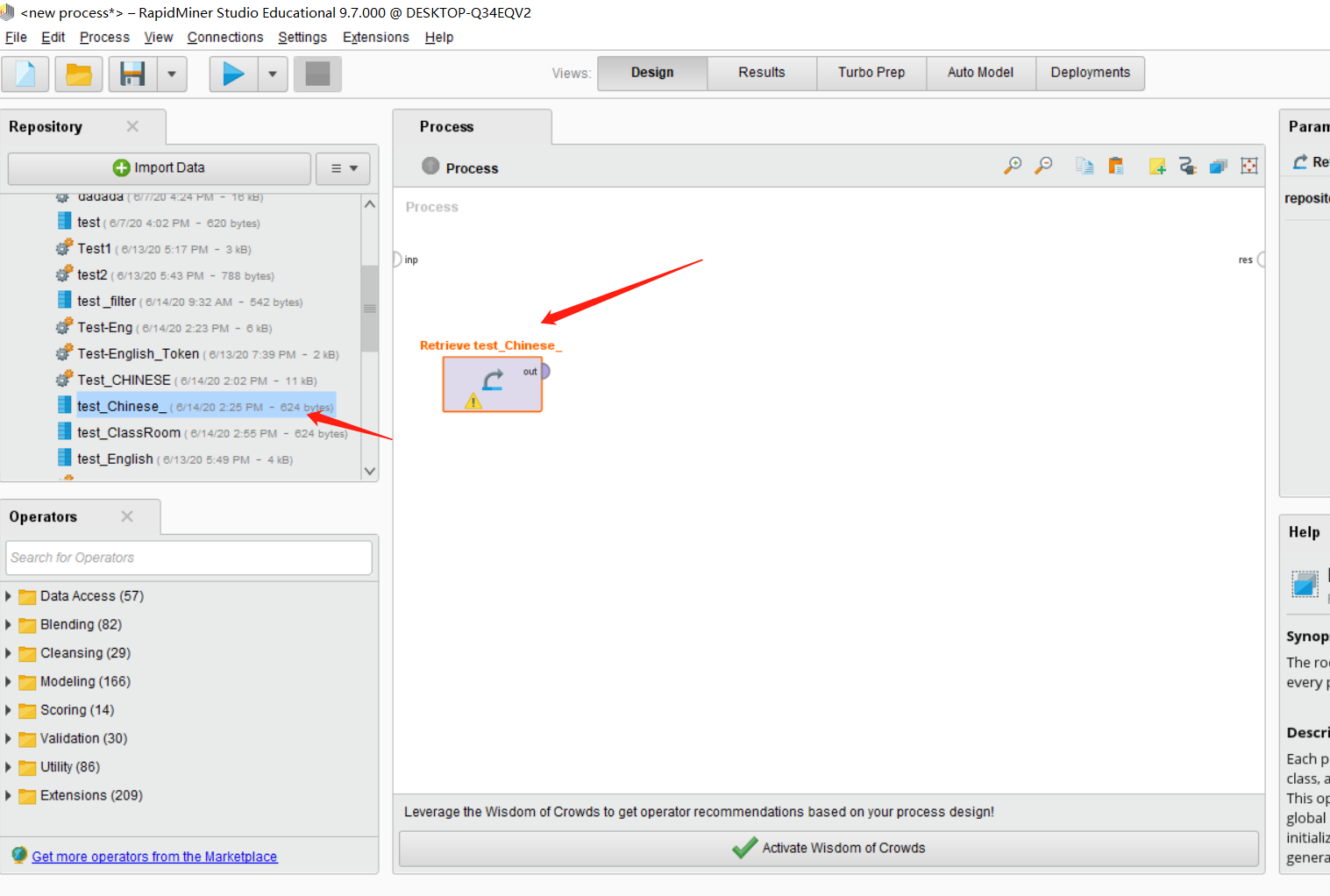
之后在左下角找到Nominal to Text这个Operators。并将其拖入主界面,将第一个控件的out连接这个控件的exa。
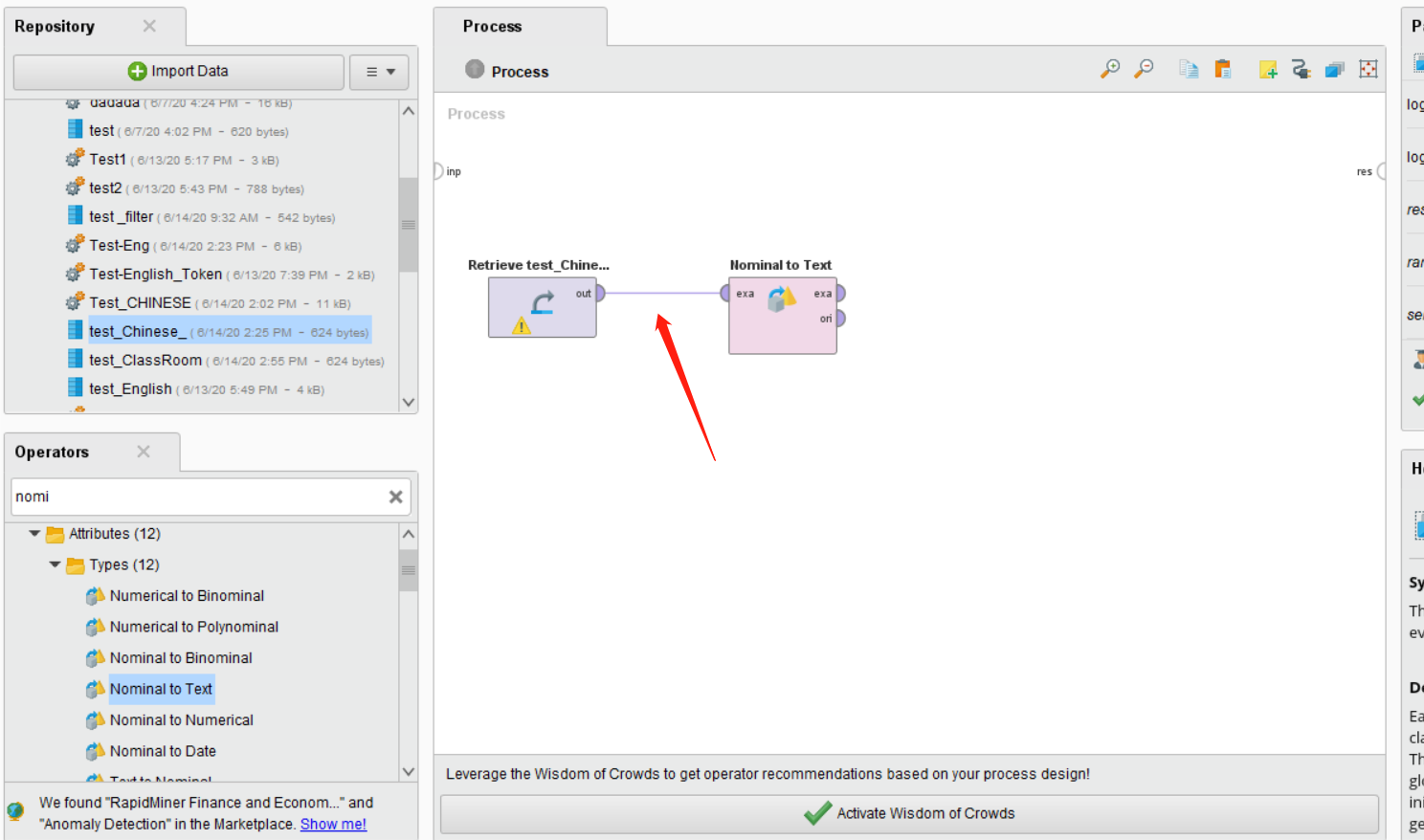
之后我们在搜索Process Document from Data,将其拖入主界面,然后将Nominal to Text控件的exa连接Process Document from Data控件的exa。
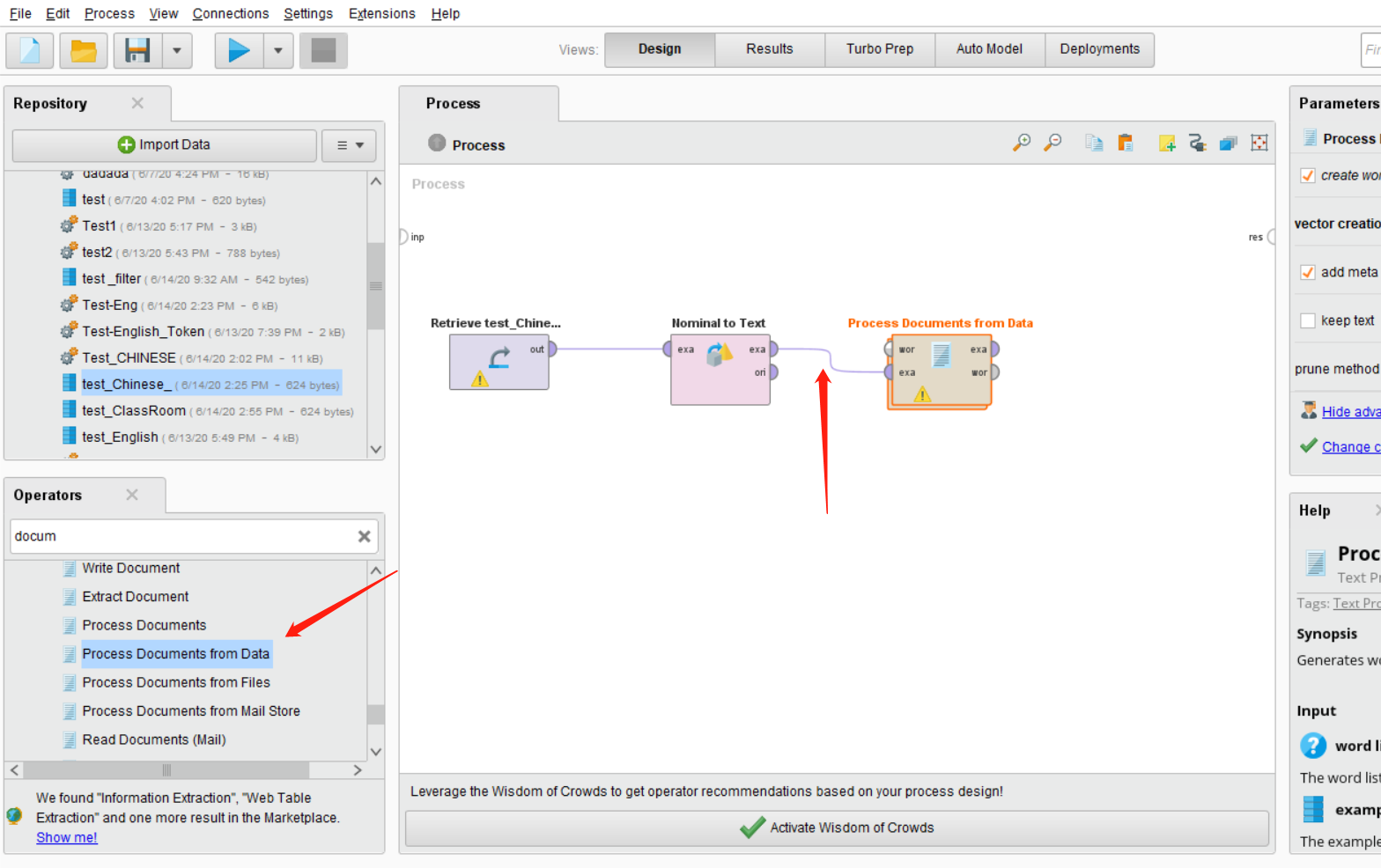
这时候我们可以点击Process Document from Data,在右边可以看到这个控件的功能。vector creation我们目前需要选择TF-IDF,剩下都默认就好。
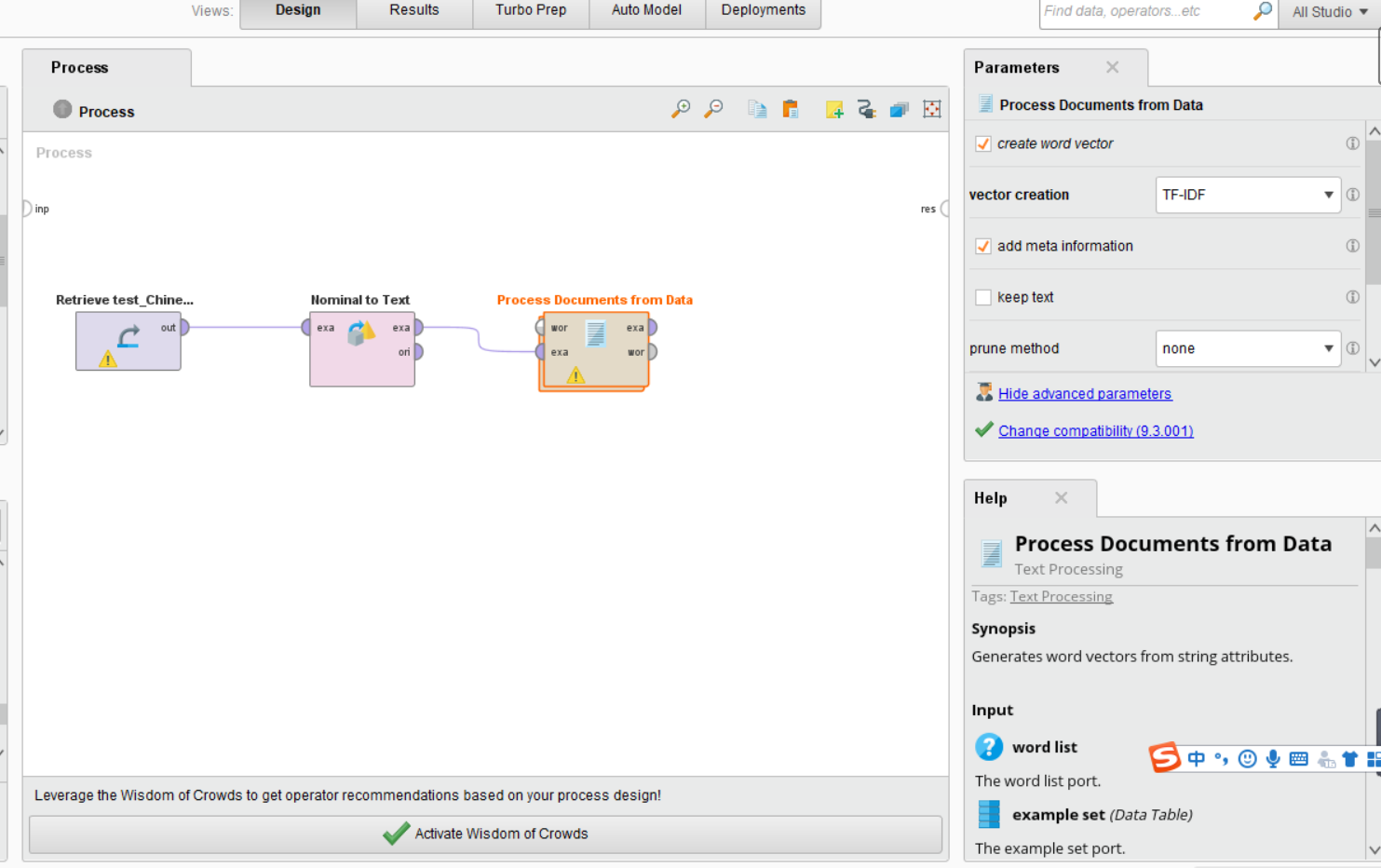
这时候我们在双击Process Document from Data,进入这个控件里面。会出现以下画面:
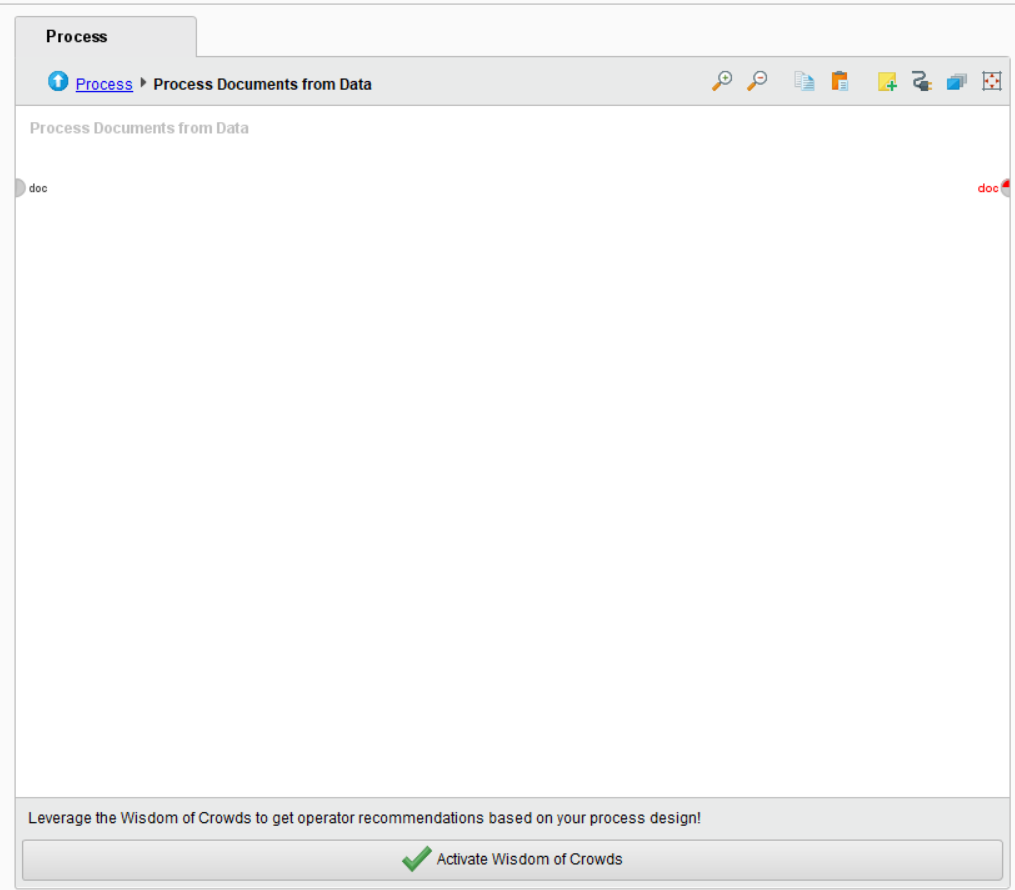
这时候在搜索Document to Data,并将其拖入主屏幕,点击这个控件,在右边必须填写两个不相等的值。目前我填写的是text1和text2。
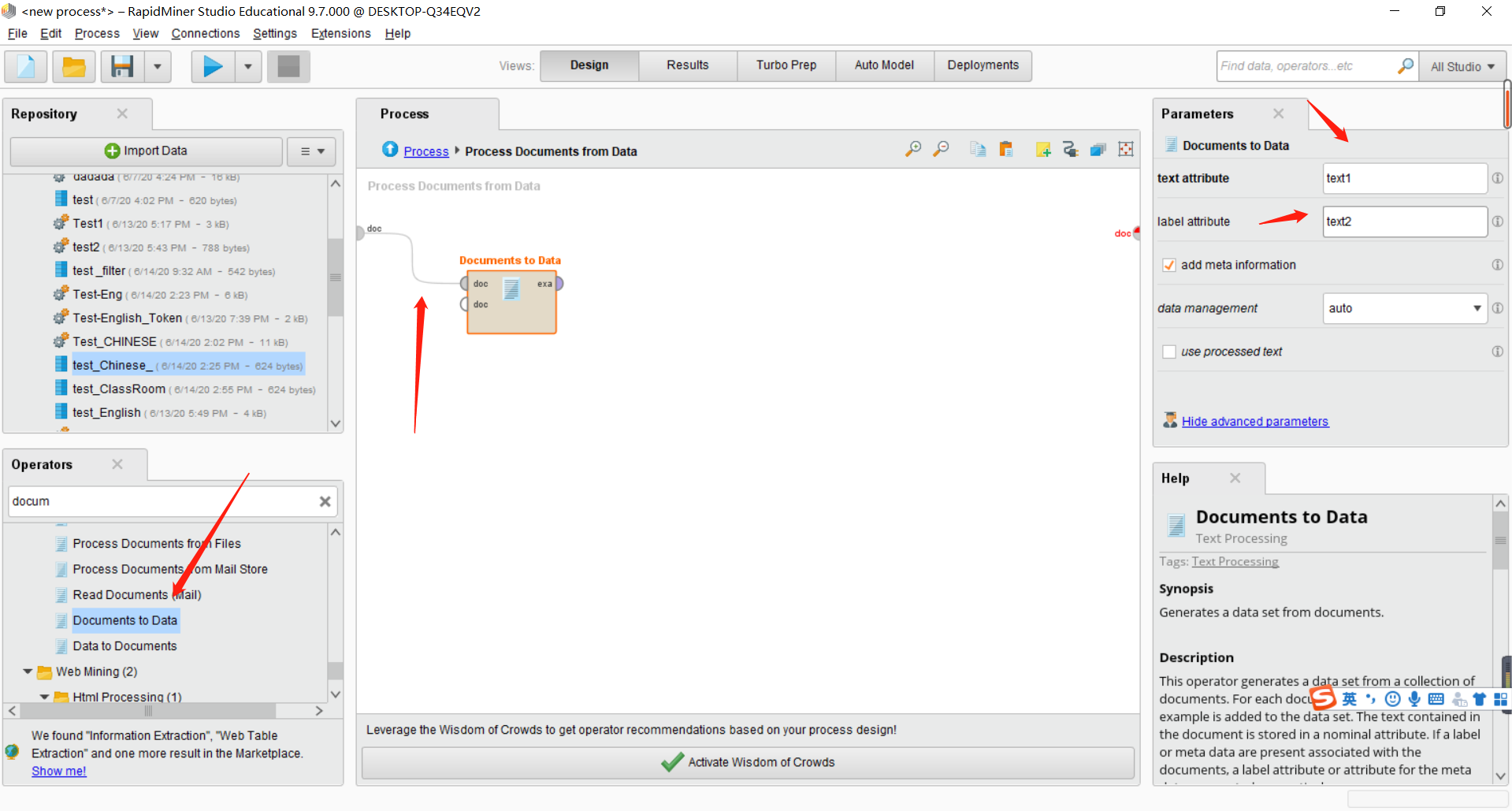
之后我们在搜索python,将其拖入到主界面里。将Documen to Data的exa连接到python的第一个inp接口。如下图所示。
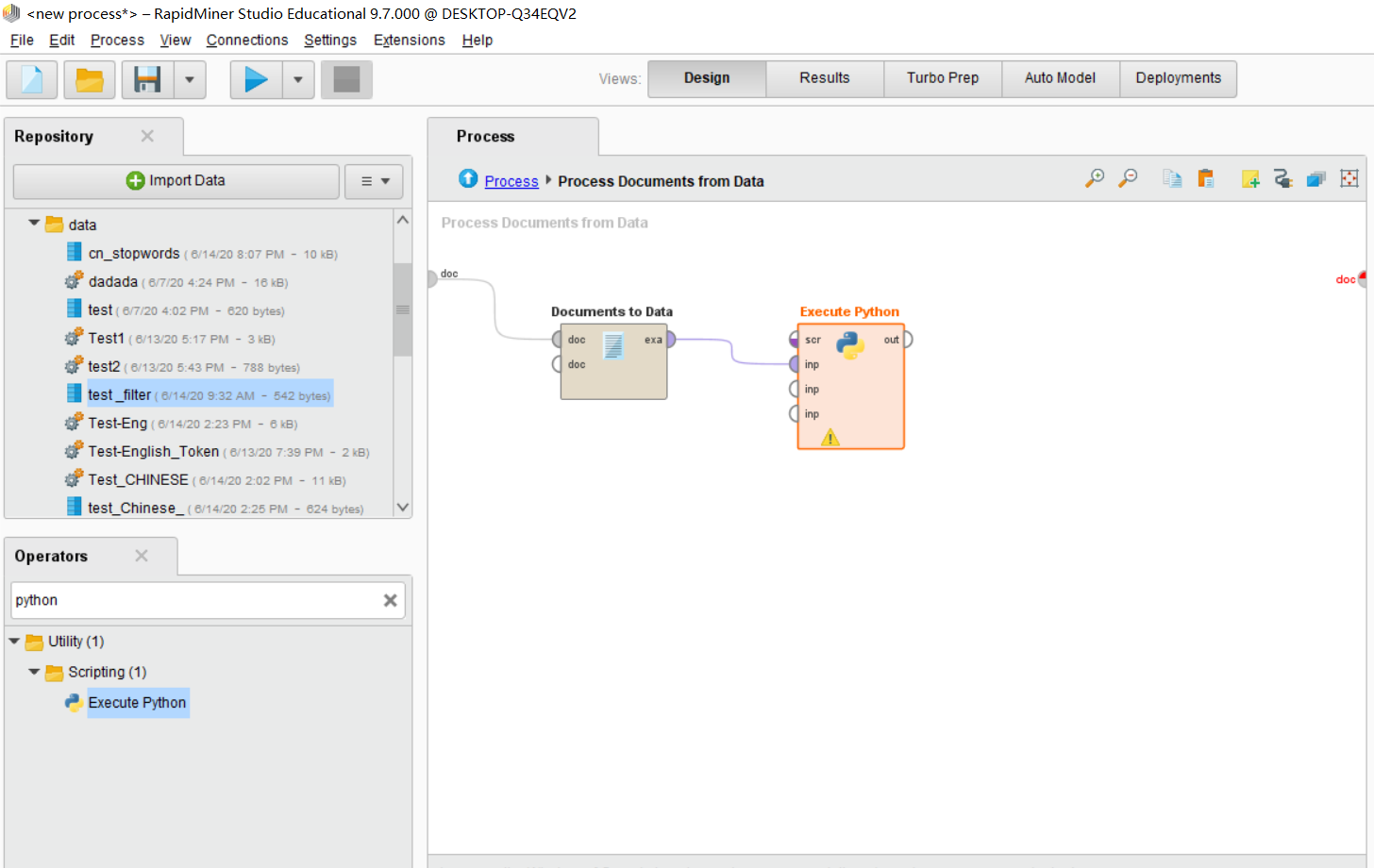
之后点击Execute Python,在右侧点击Edit Text,如下图所示。
之后导入下面的代码(中文分词操作):
import pandas as pd
import jieba
import jieba.analyse
#里面很多无关紧要的代码,但是可以测试用。
# rm_main is a mandatory function,
# the number of arguments has to be the number of input ports (can be none)
def rm_main(data):
# output can be found in Log View
segments = [] #功能留用
framedata = []
for index, row in data.iterrows():
content=row[0]
words = jieba.cut(content)
splitedStr = ''
for word in words:
#停用词判断,如果当前的关键词不在停用词库中才进行记录
segments.append({'word':word, 'count':1})#可有可无
splitedStr += word + ' '
framedata.append({'splited word':splitedStr})
Sgdata = pd.DataFrame(framedata)
#your code goes here
list1 = []
for i in range(len(Sgdata)):
lis = Sgdata.iloc[i][0].strip().split(' ')
list1.append(lis)
# connect 2 output ports to see the results
Sgdata = pd.DataFrame(list1)
return Sgdata之后拖入我们所需要的停用词列表数据到主界面,并导入另一个python控件,将第一个python控件的out连接第二个python脚本的第一个inp接口,将停用词的out连接第二个python脚本的第二个inp接口。如下图所示:
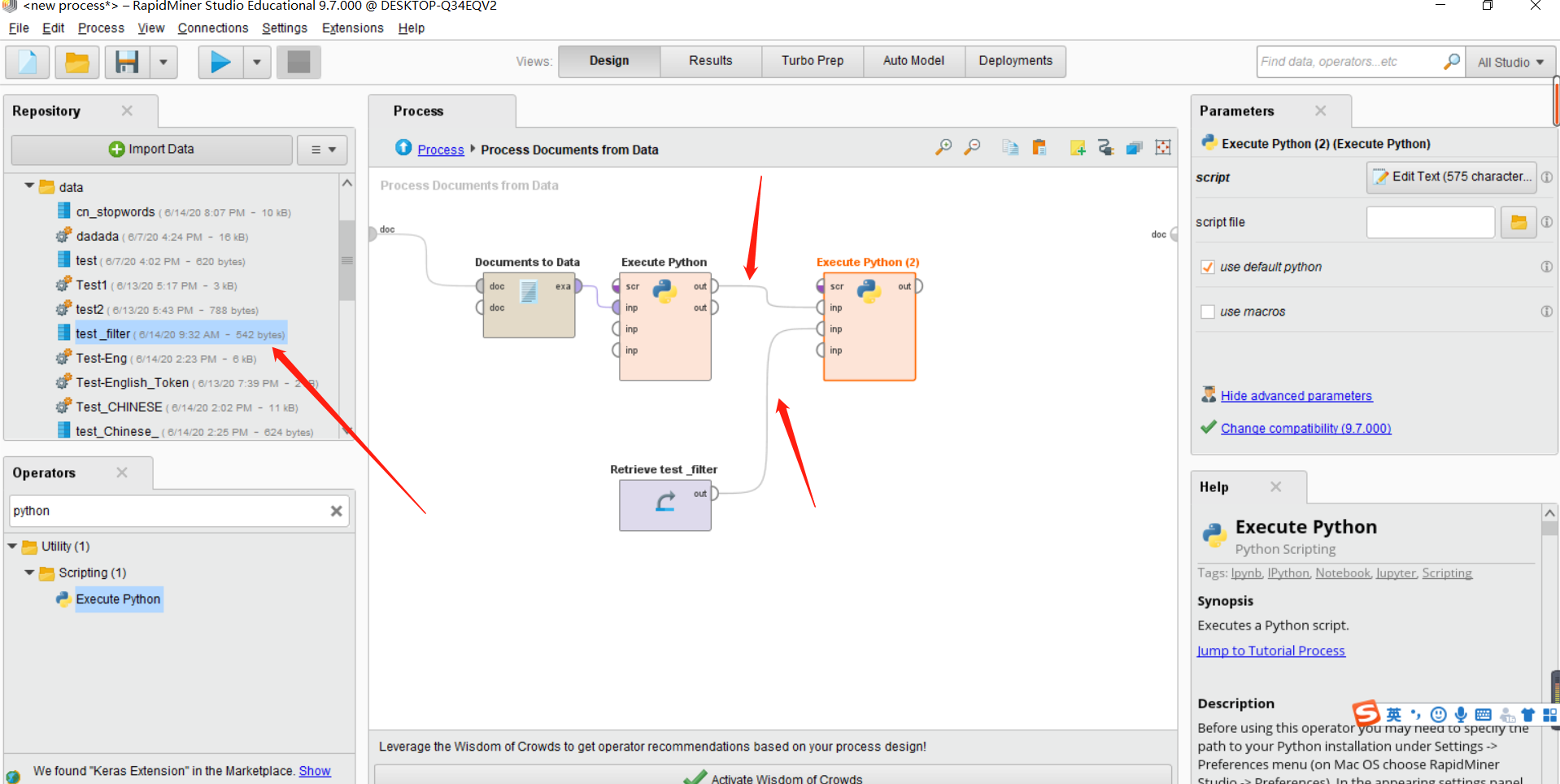
在第二个python控件导入以下代码(去除停用词):
import pandas as pd
import numpy as np
def rm_main(data,data1):
# output can be found in Log View
listdata = np.array(data1)
stopwords = listdata.tolist()
segments = [] # 功能留用
col=k=data.shape[1]
My_content=[]
framedata = []
j = 0 # 记录列数
for index, row in data.iterrows():
My_content.append([])
for i in range(0,k):
content=row[i]
My_content[j].append(content)
splitedStr = ''
for l in range(0,col):
stop = []
if My_content[j][l]!=None:
stop.append(My_content[j][l])
if stop not in stopwords:
# 记录全局分词
segments.append({'word': My_content[j][l], 'count': 1})
splitedStr += My_content[j][l] + ' '
j = j + 1
framedata.append({'splited word': splitedStr})
Sgdata = pd.DataFrame(framedata)
# your code goes here
list1 = []
for i in range(len(Sgdata)):
lis = Sgdata.iloc[i][0].strip().split(' ')
list1.append(lis)
# connect 2 output ports to see the results
Sgdata = pd.DataFrame(list1)
return Sgdata之后我们在搜索Nominal to Text这个Operators。并将其拖入主界面,将第二个python控件的out连接这个控件的exa。如下图所示:
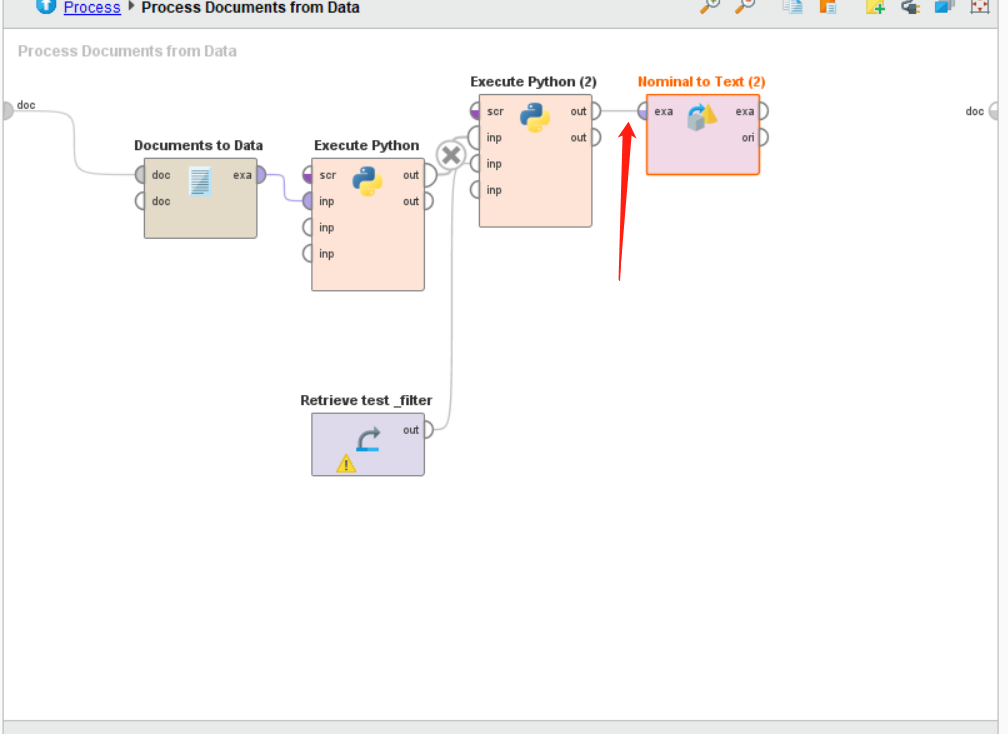
之后我们在搜索Data to Document这个Operators。并将其拖入主界面,将Nominal to Text控件右侧的exa连接这个控件的exa,将Data to Document右侧的doc接口连接右上角的doc接口。如下图所示:
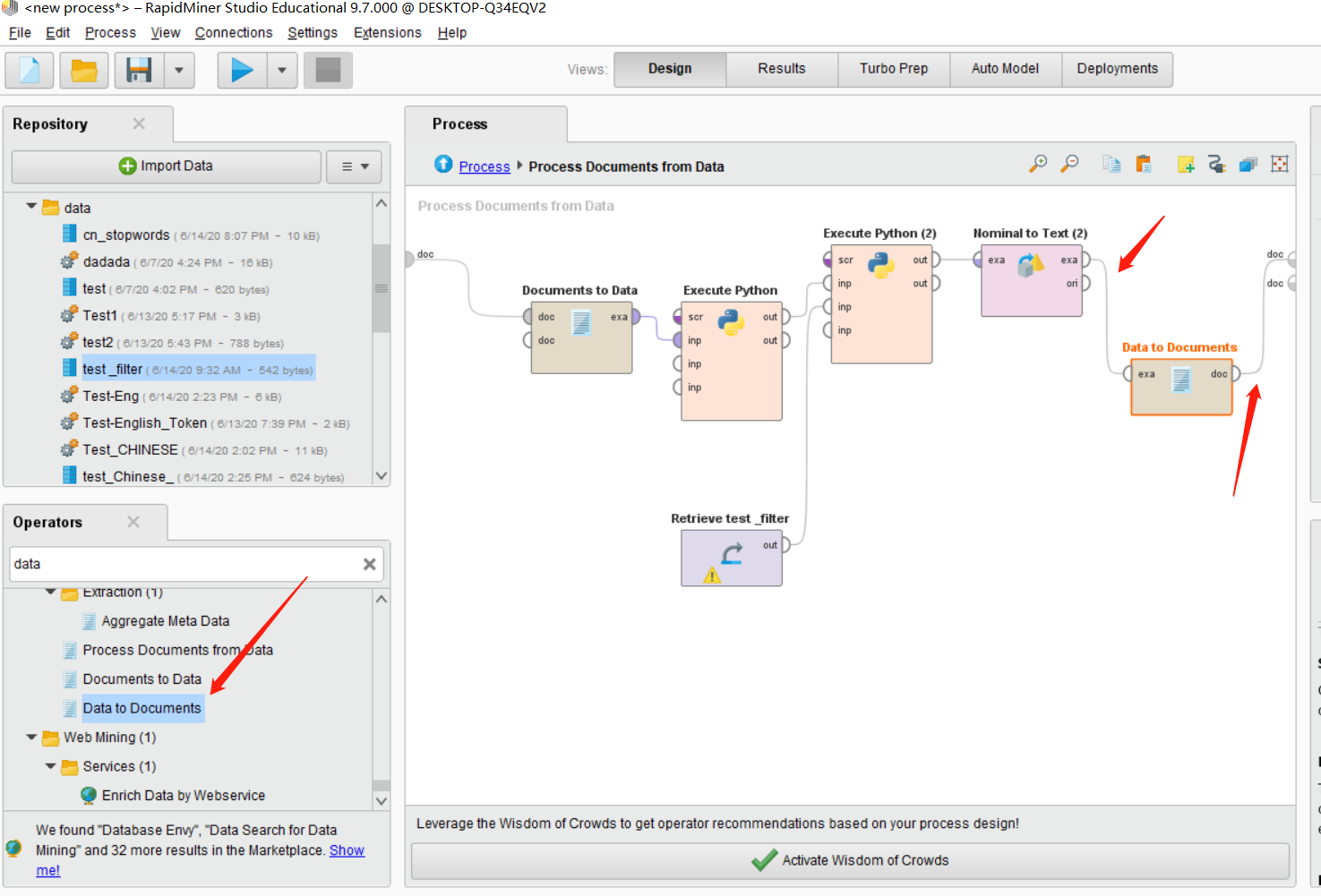
这时候我们里面的全部流程就做完了。
下面我们回到主界面。
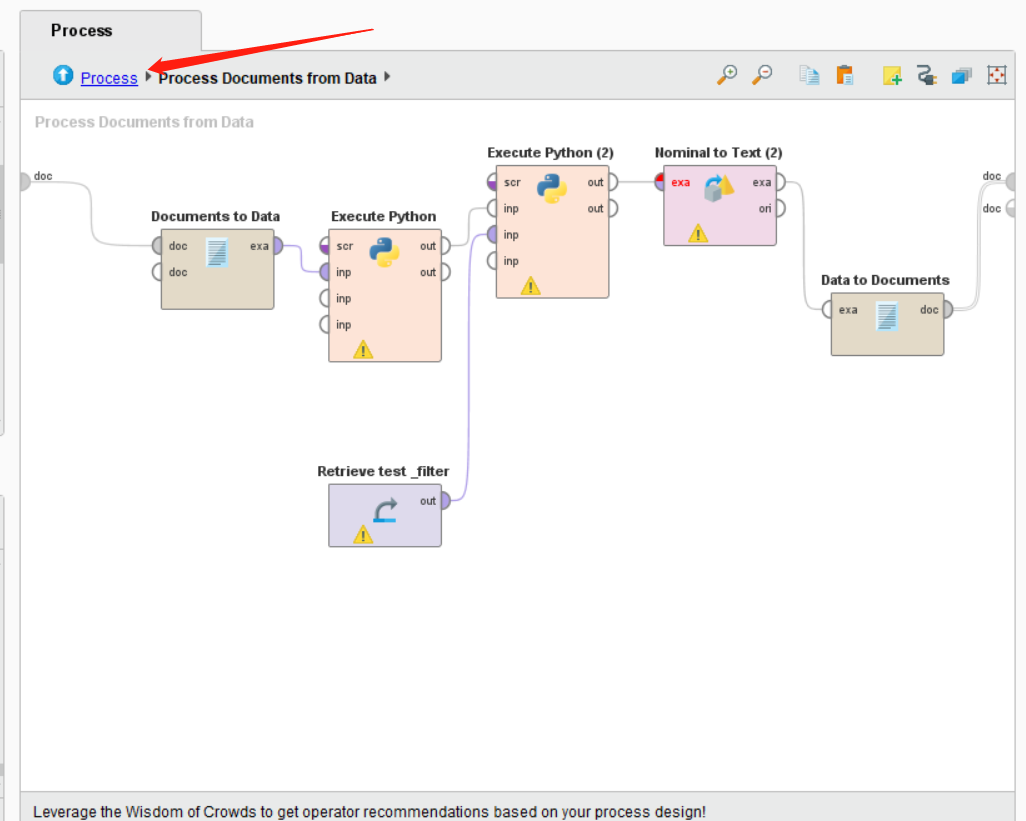
之后我们在搜索K-means这个Operators。并将其拖入主界面,并按照如图所示连接所有的线。如下图所示:
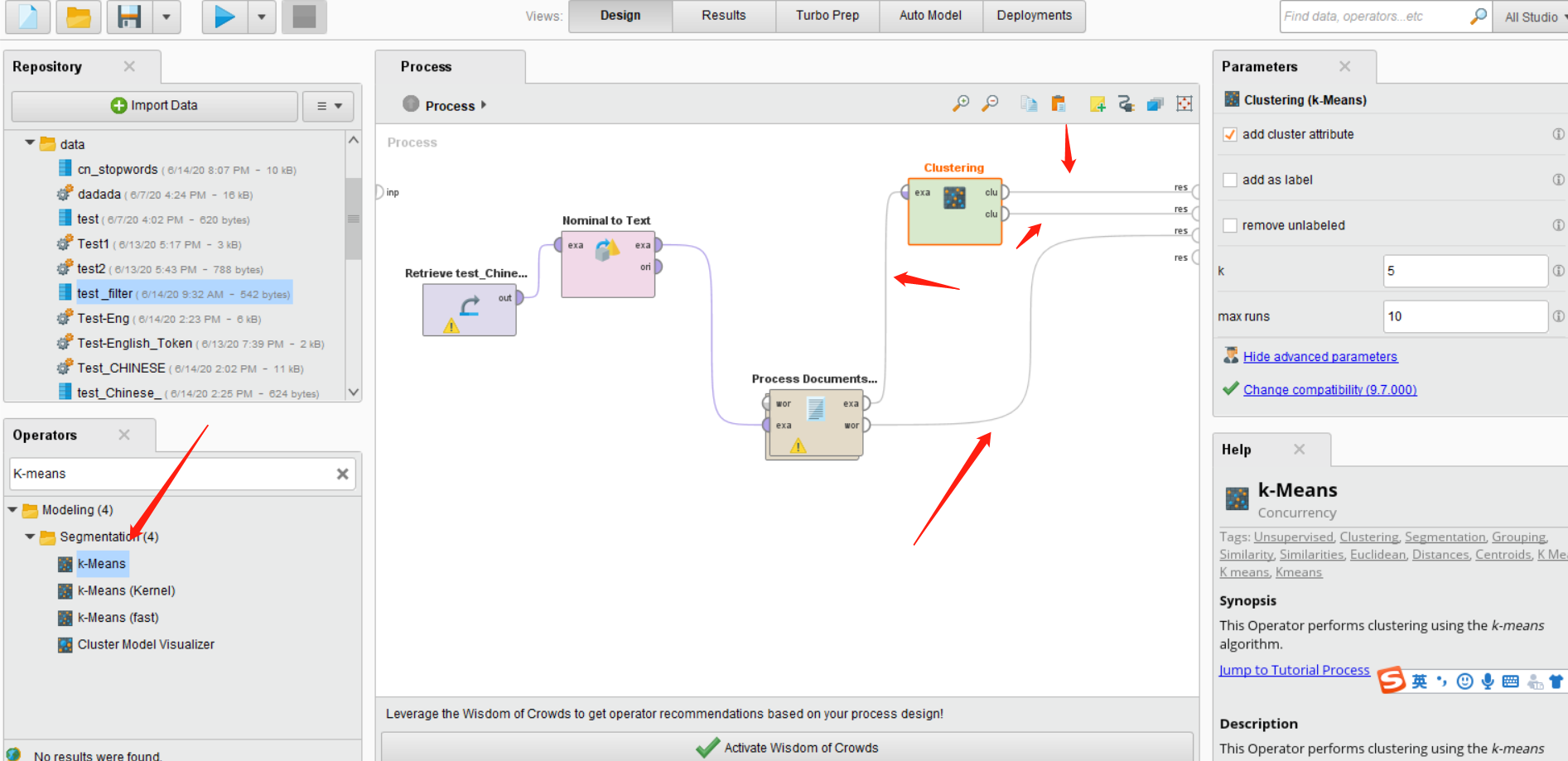
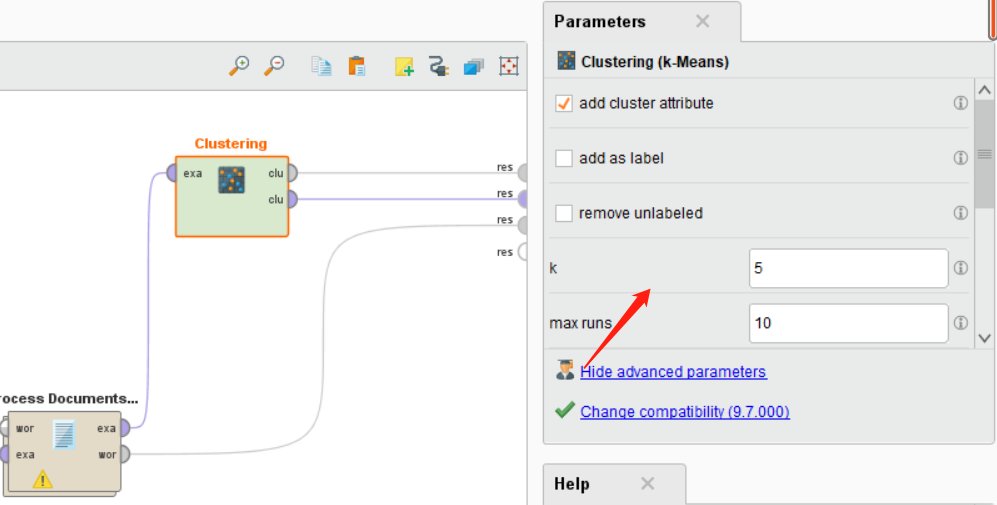
我们可以点击Clustering这个控件,然后在右侧设置我们想设置的数值。
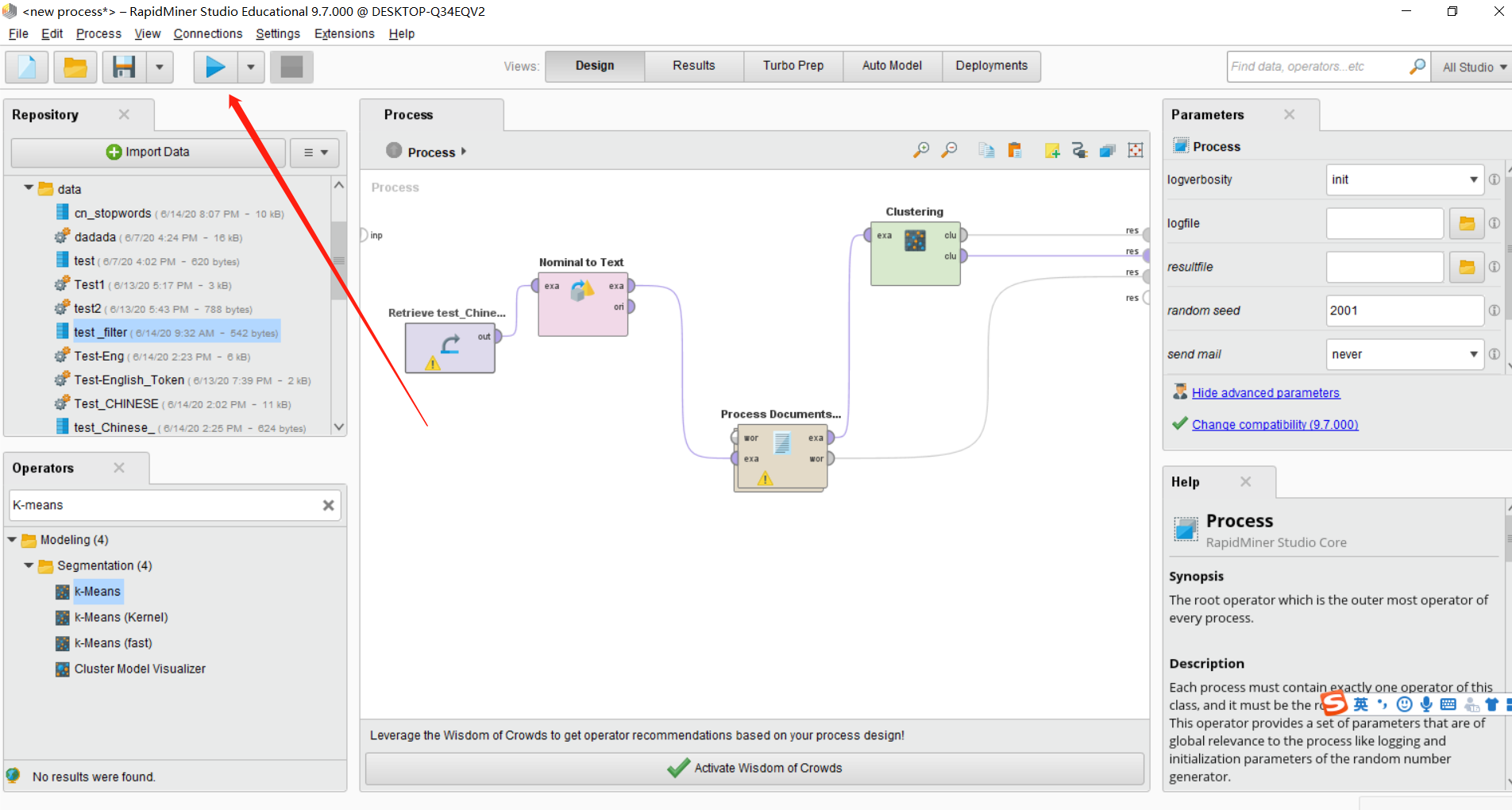
Fourth: 运行整个流程
点击在左上角的蓝色小箭头即可运行您的项目,稍等片刻,即可出现所有的结果。
那么我们大功告成!
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!